



Wouldn’t it be convenient to have an AI-powered chatbot that could answer questions about your app data in Kintone? For this use case, ChatGPT and other LLMs are promising, but not sufficient on their own. For consistently relevant results, retrieval of context is needed. This project explores Retrieval Augmented Generation (RAG), which fetches contextual data related to a user’s question. This allows for the chatbot to provide a much more relevant answer to the user’s inquiry, with sources referenced.
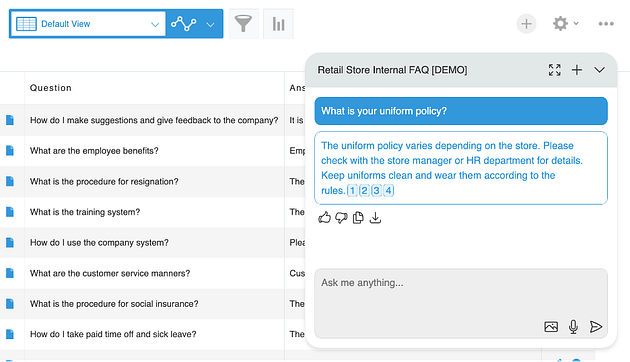
A chatbox is used to answer an employee users’ question about HR documents stored in the datasource app.
Agenda:
- Introduction
- Setting up the Data Source app
- Cloning Repository
- Configuring Settings
- Running the Backend
- Running the Frontend
Introduction:
The project repository can be found here at this GitHub link.
Retrieval Augmented Generation (RAG) architecture improves the relevance of an AI chatbot’s answers. This RAG-powered Chatbox allows a user to ask specific questions about data stored in a Kintone app. This example allows an employee user to ask about HR department documents stored in Kintone via a Chatbox frontend app.
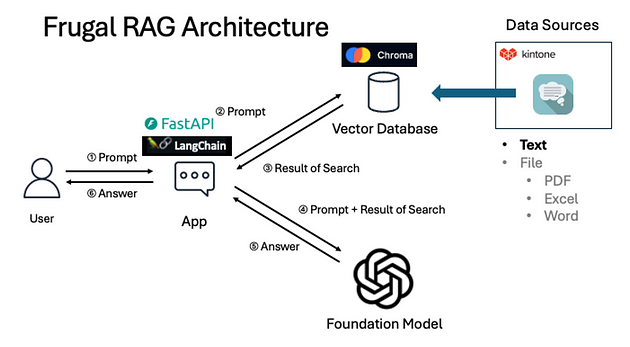
More specifically, the LangChain framework uses an OpenAI model that answers the user’s questions based on context stored in a Chroma database, via a FastAPI python server.
LangChain allows for many steps (from sentence transformation to API calls) and integrations with LLMs (Large Language Model such as ChatGPT). Additionally, LangChain also uses vector databases like Chroma, which can store documents and contextual data. A chain of steps defined in LangChain help optimize the responses of the LLM Chatbot.
Chroma is a vector database that converts natural language data (example, HR documents) into high-quality embeddings via sentence transformers. When the question is asked by the user, only the embeddings related to the question are retrieved from Chroma. These embeddings are used as context in the prompt that is provided to OpenAI model, which then formulates the response to the user.
This AI-powered chatbot app returns an answer related to the user’s question, by querying a Chroma database that stores data from the “Retail Store Internal FAQ” Kintone app.
An app in Kintone called “Retail Store Internal FAQ” stores PDFs, Excel files, and record data related to the store’s company policy. This app is referred to as the Data Source app (see diagram below).
Note: Here is an app template of the “Retail Store Internal FAQ” apps, and sample data.
Setting up the Data Source app:
The data source app called “Retail Store Internal FAQ” contains question and answer data related to the company policy.
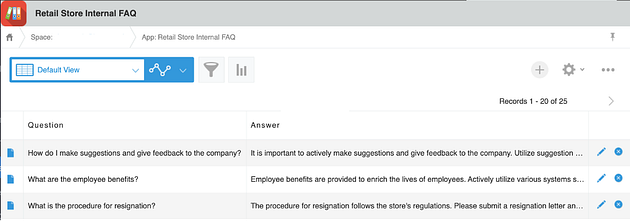
The API Token of this app, and the subdomain are needed for the Frugal RAG app. The python backend script from this project will pull data from this app, transform the sentences into embeddings, and store them in the Chroma database.
Cloning the Repository:
Create a new empty folder.
Open the project in VS Studio Code.
Clone the repository in the folder by running the following command in the terminal:
git clone https://github.com/yamaryu0508/kintone-rag-example
Backend folder contains the python server for generating responses.
Frontend folder contains the TypeScript project for the Chatbox user interface.
Images folder contains diagrams of the architecture, and a sample screenshot of the chatbox.
Next, install the python packages for the backend by running:
cd kintone-rag-template
cd backend
cd app
pip install -r requirements.txt
Next, dot env will be installed. Navigate to the backend folder in the console.
cd ..
pip install python-dotenv
Configuring Settings:
Click on the backend folder and create a file called “.env”.
Add the following code and add the Kintone API Key to the file.
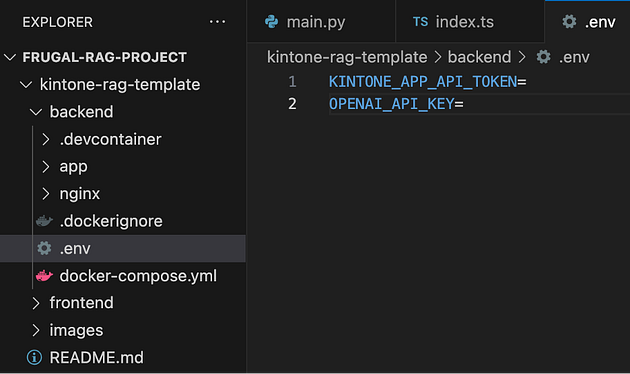
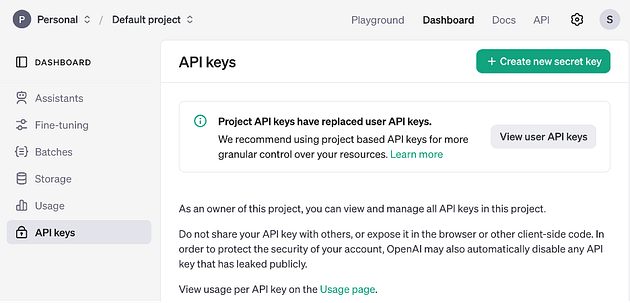
To get the token, go to OpenAI and get an API Token.
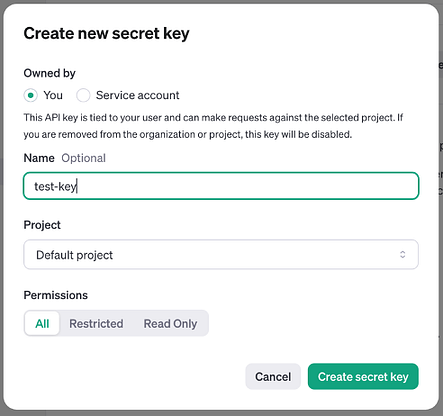
Navigate to Dashboard, then to API Keys. Generate a key and add it to the .env file.
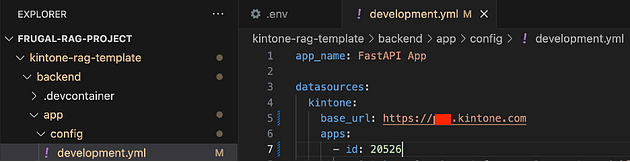
Now that the API Keys have been added, the settings stored in development.yml must be updated. Navigate to app > config and open the file.
In the file, update the subdomain in the base_url, and the app id under apps > id.
Now the configuration of the project is complete.
Running the Backend:
Install Docker. If your OS is too old to run the current version of Docker and upgrading is not desirable, use this unofficial list to find an older version of Docker. This version was used for Big Sur 11.6. Docker takes 1.9 GB of disk space.

Docker has been successfully installed.
Now you can run the following command.
Navigate to the backend folder and run Docker Compose.
cd backend
docker-compose up
Allow the changes.
The build process will proceed.
The backend app will now display in the Docker Desktop dashboard.
Expanding the backend will expose the apps running from the project.
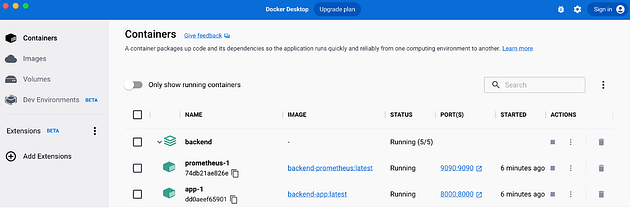
Use this cURL command in the terminal to test the newly running backend:
curl -X POST http://localhost:8000/api/chromadb/rag/query -H \
"Content-Type: application/json" -d '{"query": "What is the uniform policy?"}'
The backend’s response will log in the Docker logs. (NOTE: A warning about deprecated packages may appear. This should not affect the functionality.)
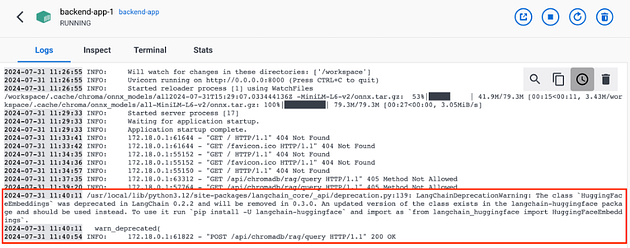
This is a sample response to the cURL command:

Running the Frontend:
Now that the backend is running, the frontend can be deployed.
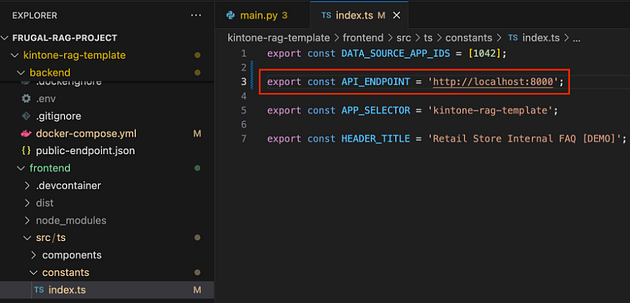
Navigate back to the VSCode project and check src > constants > index.ts to make sure the API_ENDPOINT is http://localhost:8000.
Open a second terminal.
Run the following commands in the new terminal:
cd kintone-rag-template
cd frontend
brew install yarn
yarn install yarn build
For the next step, make sure LiveServer extension is installed in VSCode. This extension will locally serve the bundled frontend project, which will be used in Kintone to display the Chatbox.

Next, run the LiveServer extension in VSCode.
This will open the locally hosted project file. Navigate to the desktop.js bundle file, and copy the URL.
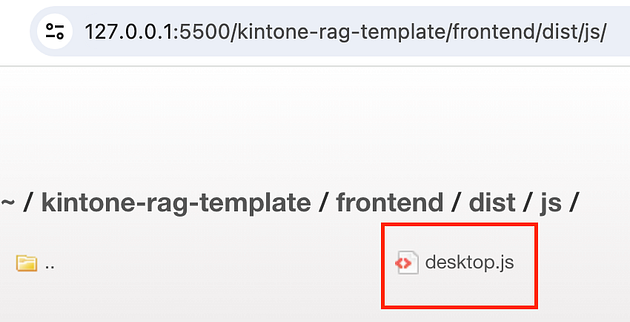
Copy the URL.

Navigate back to the Kintone app, go to the app settings and select “JavaScript and CSS Customization.”
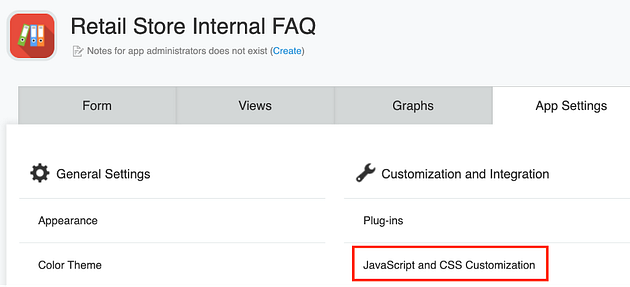
Paste the URL under JavaScript Files and update the app settings.

The chat icon has been added to the bottom right corner of the list view.
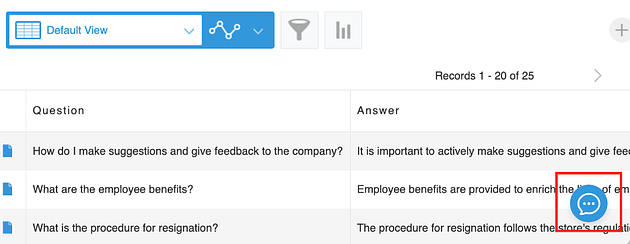
The user can now input a question and receive an answer in the Chatbox.
Conclusion
This project demonstrated how business data can be converted into context for an LLM model like ChatGPT. The Kintone app used as the data source provided records and documents to Chroma, which converted natural language to embedding format.
There are strong implications for Frugal RAG Architecture because engineers have been researching how users can efficiently ask AI about their data stored in a CRM database. Fine-tuning capabilities of OpenAI alone are not powerful enough to provide contextual answers, and it is not sufficient for this use case. Therefore, the retrieval of contextual information is necessary for LLMs to return accurate responses. This is how retrieval augmented generation (RAG) improves the relevance of the model’s answers.
Want to learn more?
If you're ready to try your hand at app building using Kintone’s drag-and-drop builder, sign up for a free 30-day trial today, no strings attached.


About the Author



